| CUDA PYTHON 并行计算基础 | 您所在的位置:网站首页 › python for循环并行执行 › CUDA PYTHON 并行计算基础 |
CUDA PYTHON 并行计算基础
|
一、CUDA异构计算基础
1.CUDA简介
CUDA(Compute Unified Device Architecture),是一种基于C/C++的编程方法,支持异构编程的扩展方法,提供了简单明了的APIs,能够轻松的管理存储系统。目前CUDA支持的编程语言包括C/C++/Python/Java/Fortran等。 2.CUDA生态
并行计算即是同时应用多个计算资源解决一个可以并行处理计算问题。 关键点有两个:一是拥有多个计算资源或处理器,二是一个大问题可以拆分为多个离散的部分同时进行。 当今的显卡拥有强大的计算能力,它有自己的计算核心和内存(在显卡中的内存称为现存),为了对CPU计算资源和GPU计算资源进行区分,异构计算中给出以下术语。 host:指的是CPU和主机内存(host memory) device:指的是GPU和显存(device memory) kernels:核函数,是一个由CPU发起的在GPU上执行的函数。 device function:只能由GPU调用的GPU上执行的函数
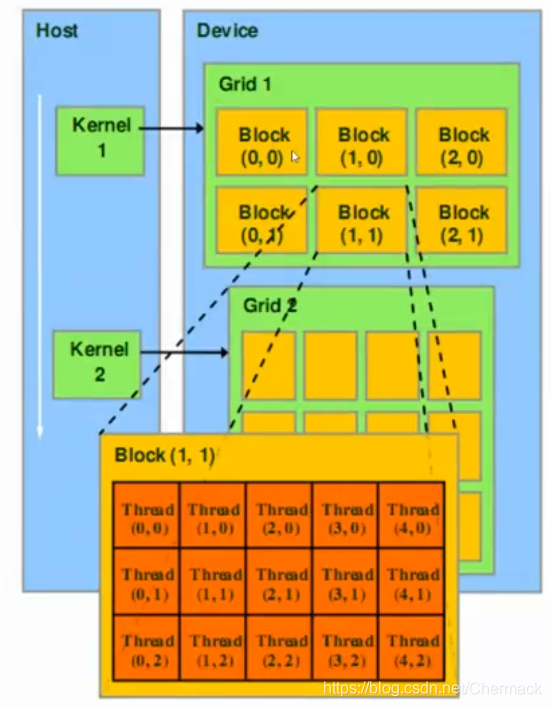
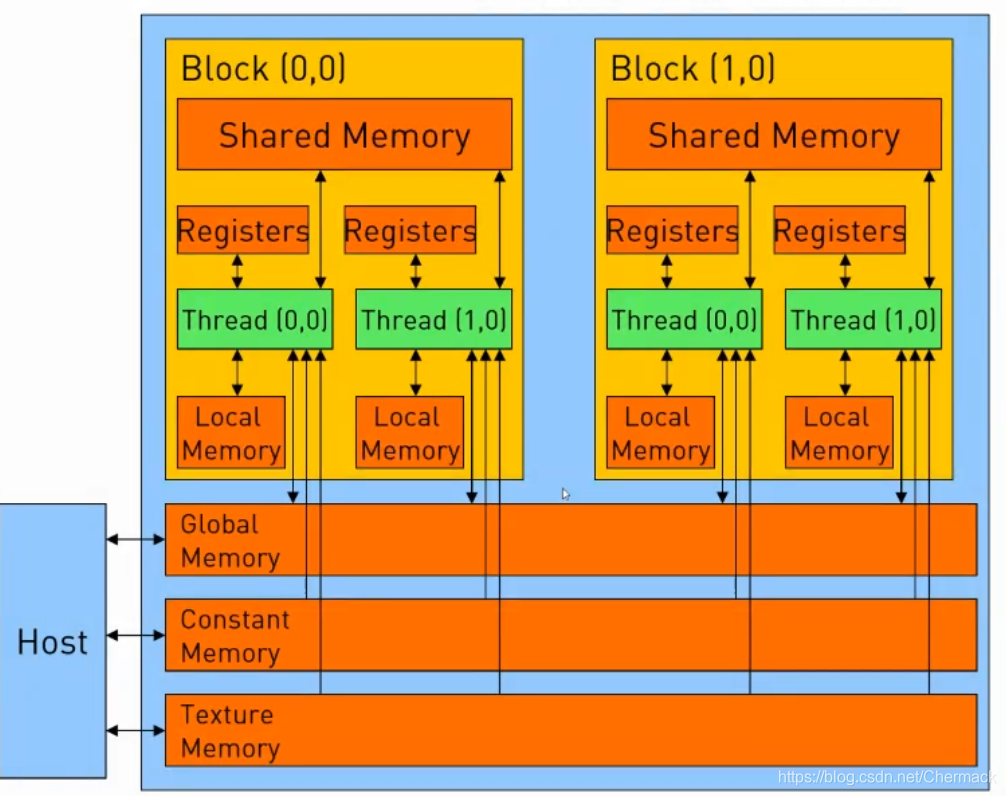
GPU结构则与CPU的设计理念有所不同,下图为GPU结构示意图,可以看到GPU中的计算核(图中深绿色部分)明显增多且数量巨大(实际的核心比示意图更多,多达上千个)。 ①首先需要将数据从主机内存复制到GPU显存,因为CPU只能访问主机内存,GPU只能访问显存,因此需要并行计算的任务数据需要从host 拷贝到device。 之前都是根据硬件的物理结构进行讨论的,接下来再对编程模型上CUDA的线程层次进行描述。CUDA将线程进行了二级分组,从大到小依次为Grid,Block,Thread。一个Grid包含多个Block,一个Block包含多个Thread。Grid与Block均可以是二维的或者三维的,一个二维的Grid和Block如图所示: 下图为一个Grid(对应一个物理GPU设备)的存储结构示意图。图中的Global Memory(全局内存),Constant Memory(常量内存)与Texture Memory(纹理内存)都属于显存的一部分,与Host主机内存相对,在每一个Block之中又有Shared Memory(共享内存)提供给该Block所有线程的共享内存。每一个Thread(线程)又拥有自己的寄存器组(Registers)和本地内存(Local Memory)。 |
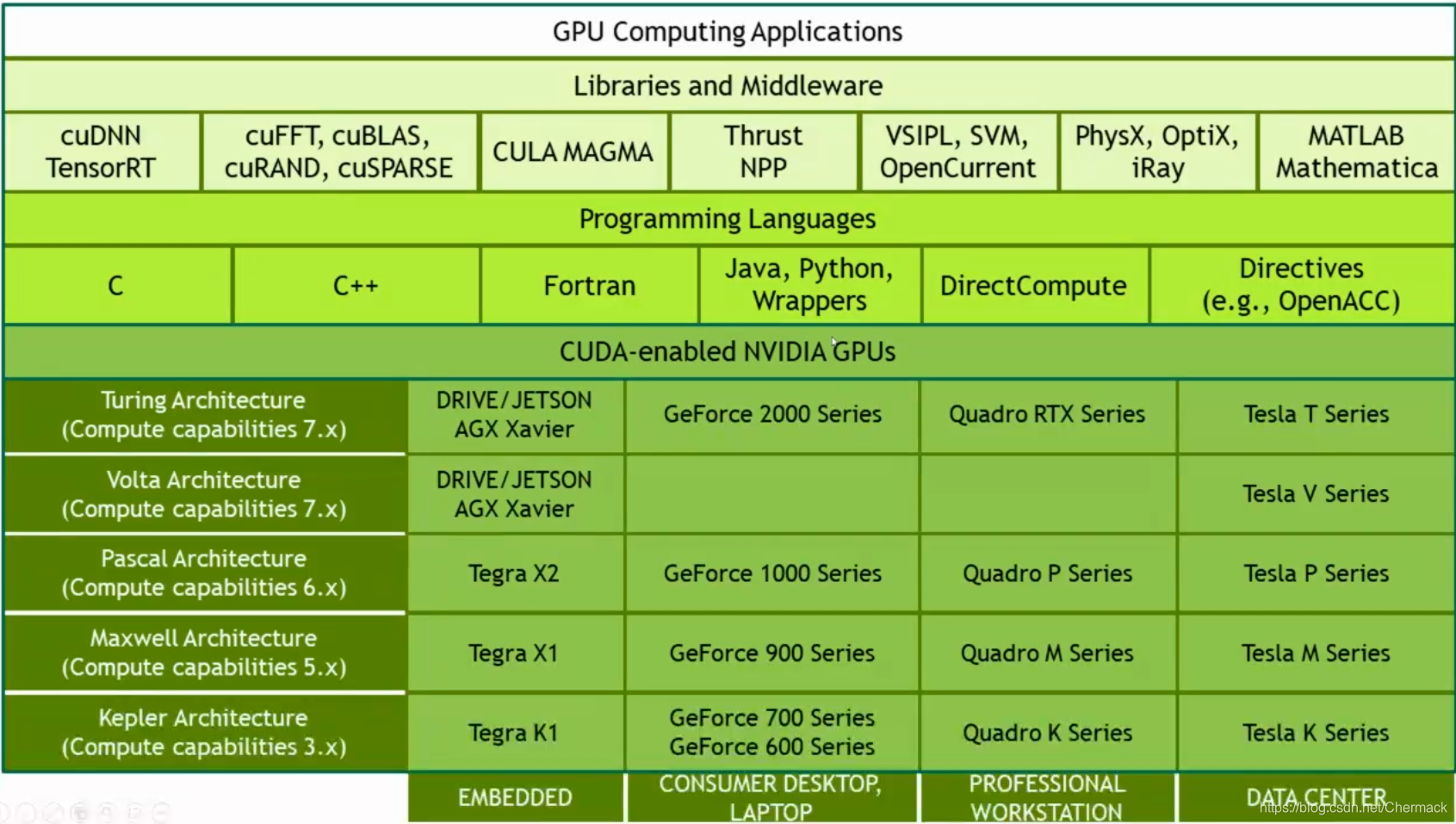 上图从上到下依次为:基于GPU计算的应用程序,一些GPU计算的库与中间件,编程语言,不同架构的GPU设备。
上图从上到下依次为:基于GPU计算的应用程序,一些GPU计算的库与中间件,编程语言,不同架构的GPU设备。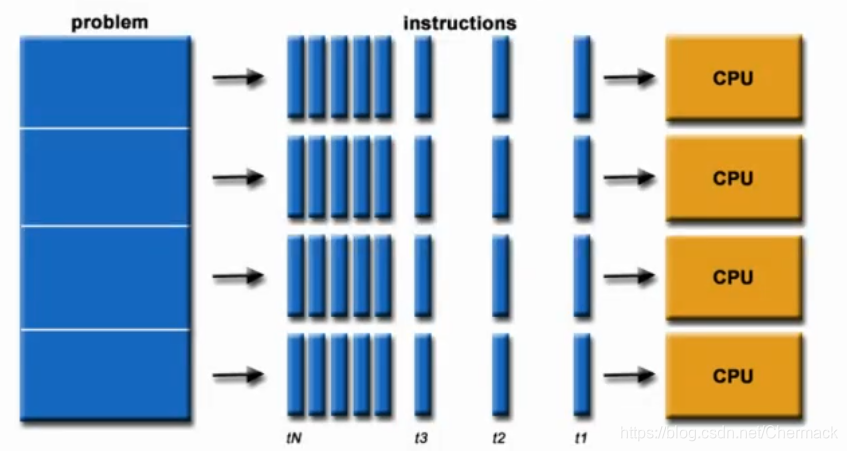

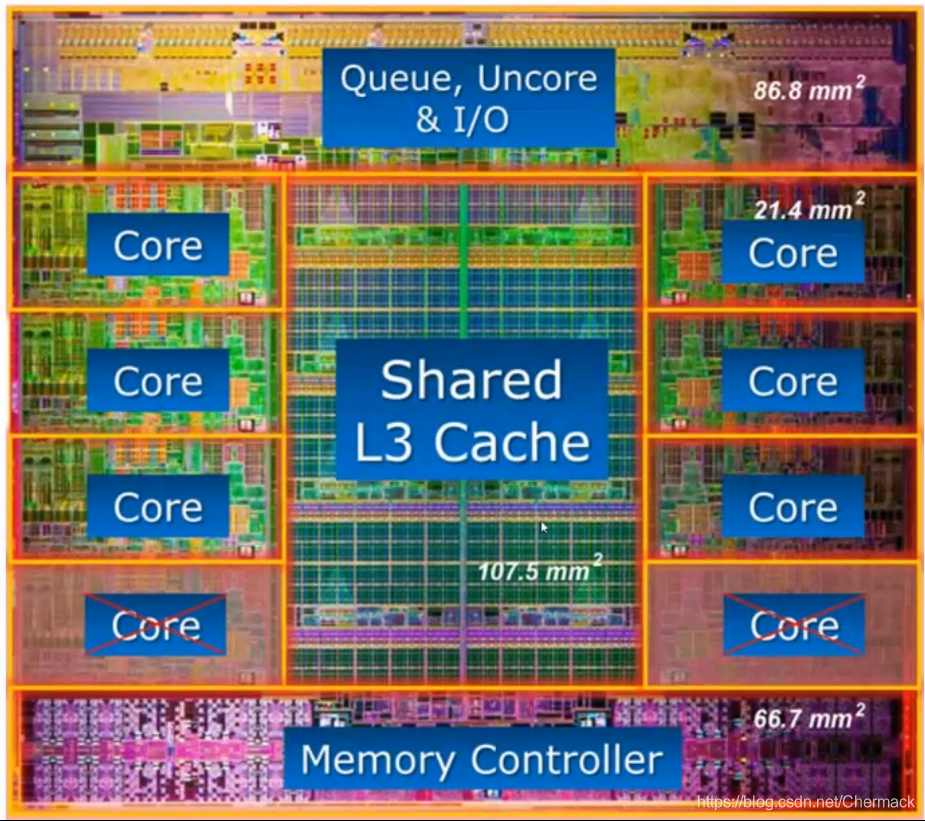 上图是一个8核心CPU内部结构图,可以看到核心(Core)所占的芯片的面积大概只有三分之一,更多的空间被用于作为存储(高速缓存Cache和内存控制器等)。
上图是一个8核心CPU内部结构图,可以看到核心(Core)所占的芯片的面积大概只有三分之一,更多的空间被用于作为存储(高速缓存Cache和内存控制器等)。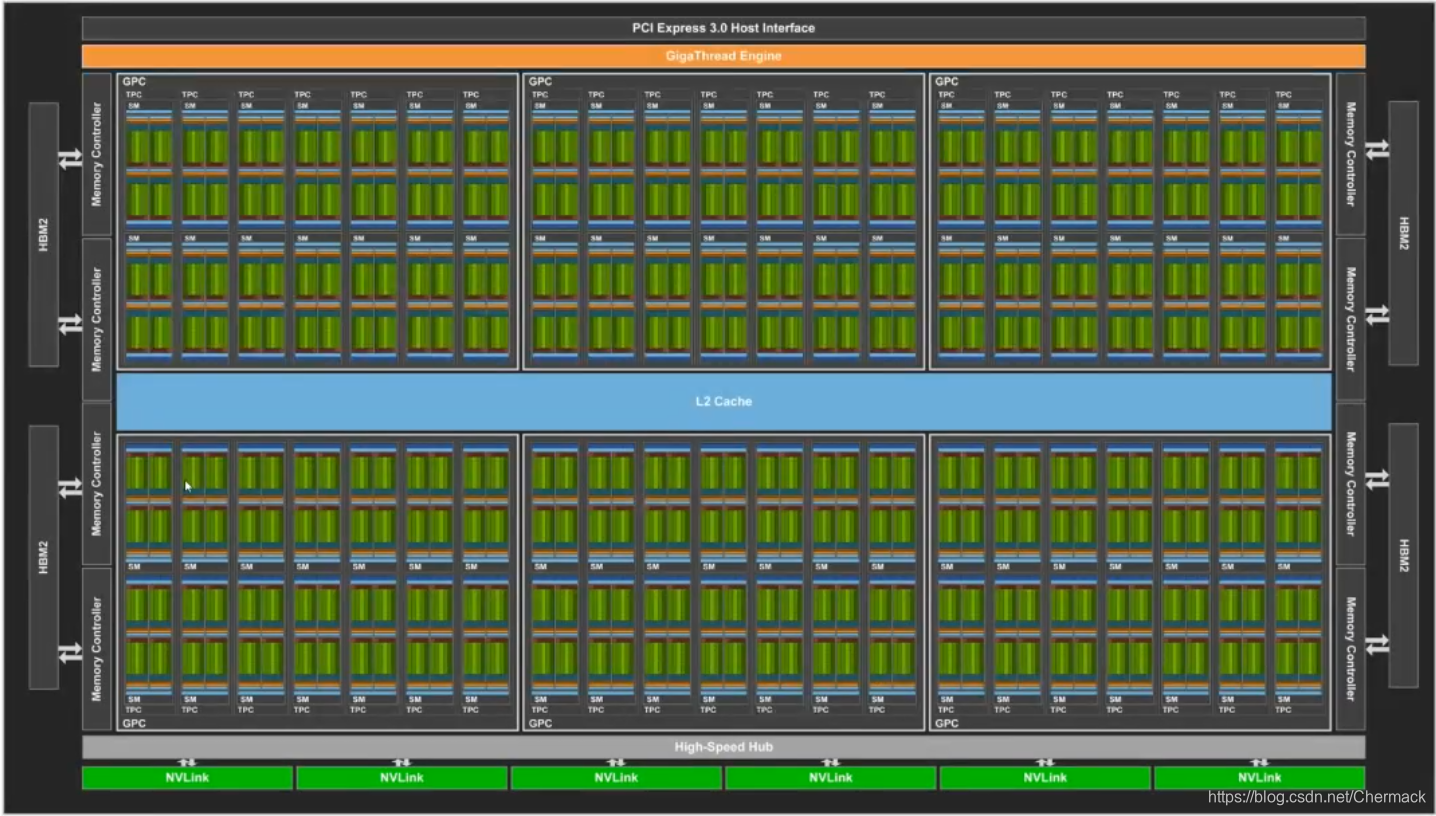 可以看到计算单元又被划分到不同的SM(stream multi-processor,流多处理器) 中,其中又包括了处理不同数据的核,有用于双精度浮点型计算的FP64,整数型计算的INT,单精度计算的FP32以及用于深度学习的TENSOR CORE以及计算之外寄存器和缓存等。
可以看到计算单元又被划分到不同的SM(stream multi-processor,流多处理器) 中,其中又包括了处理不同数据的核,有用于双精度浮点型计算的FP64,整数型计算的INT,单精度计算的FP32以及用于深度学习的TENSOR CORE以及计算之外寄存器和缓存等。 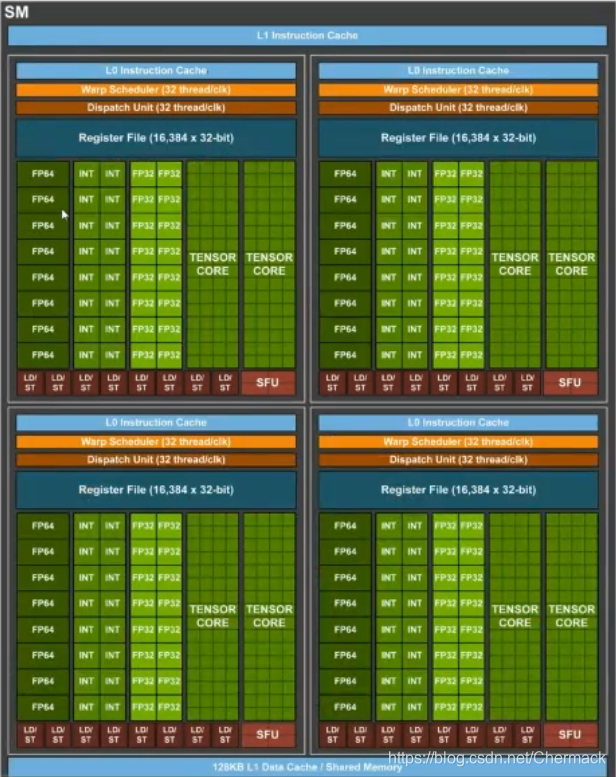
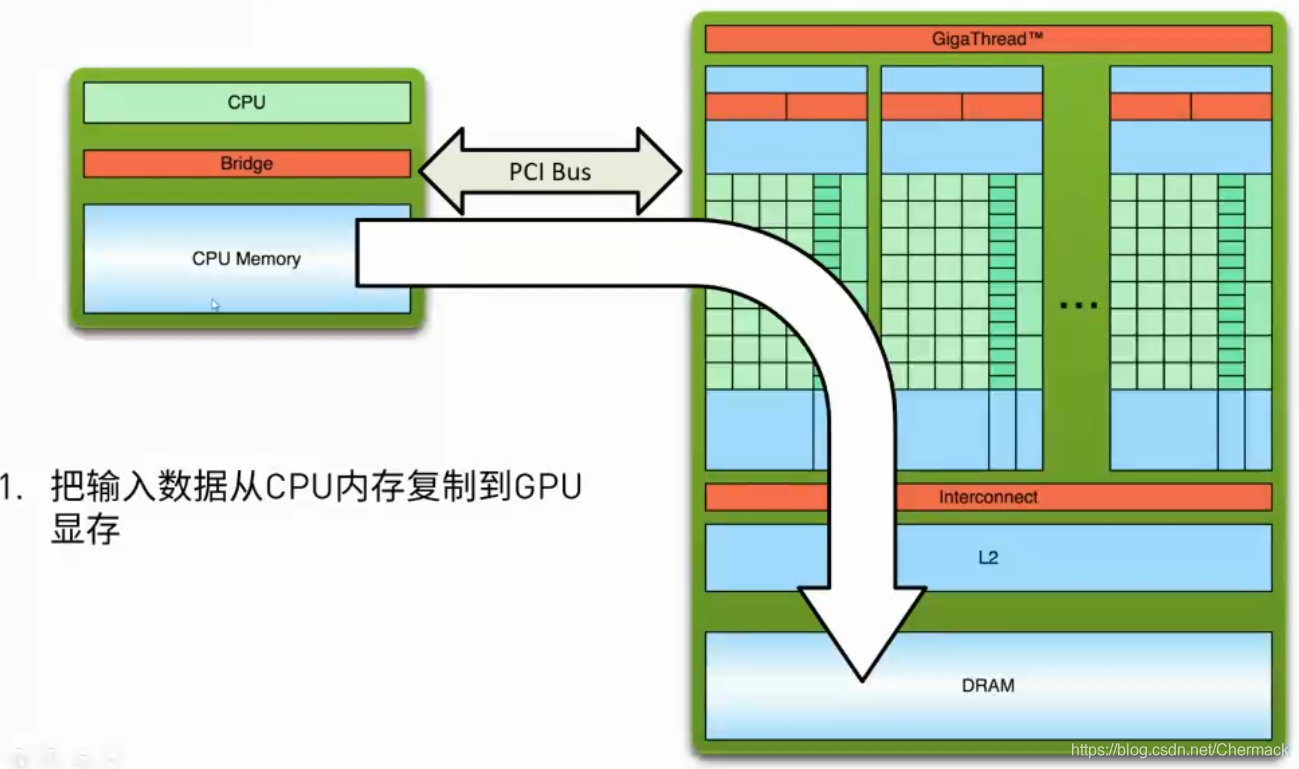 ②然后,CPU会下发指令给GPU,使其加载GPU程序并进行执行。
②然后,CPU会下发指令给GPU,使其加载GPU程序并进行执行。 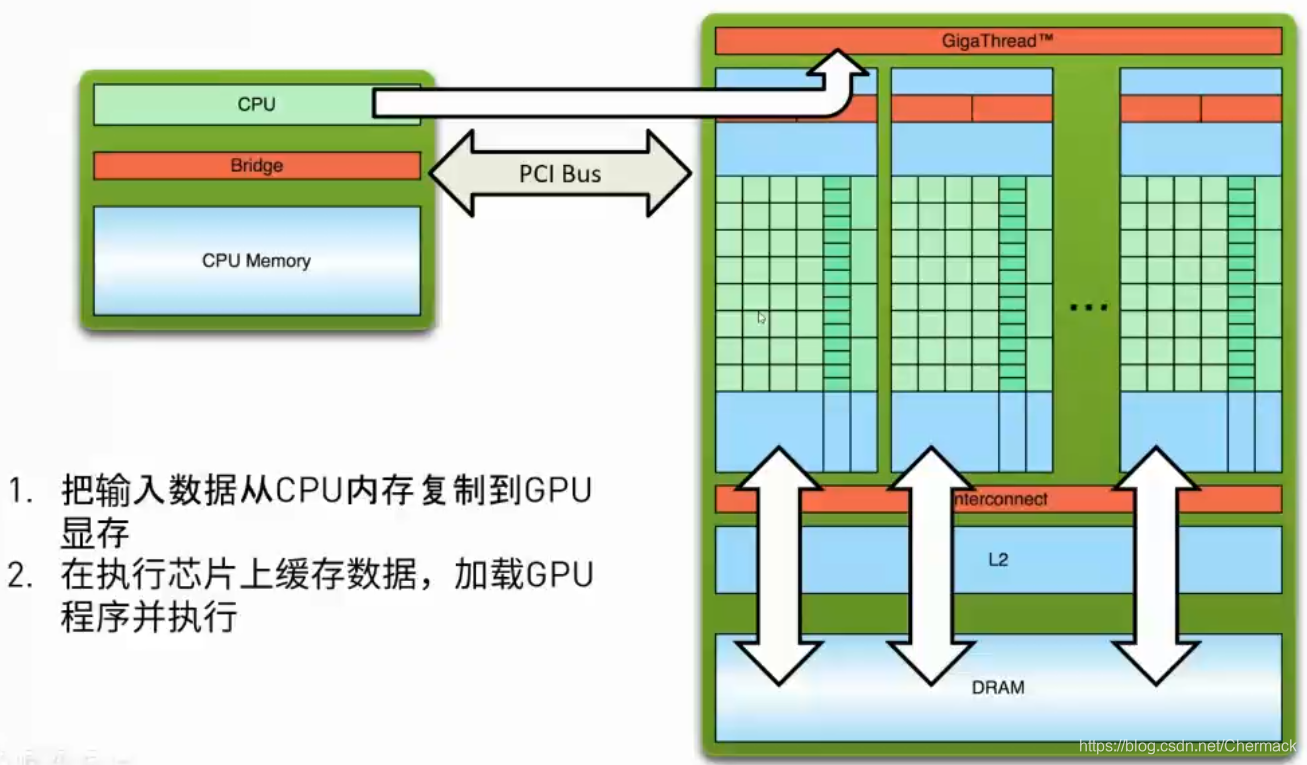 ③GPU程序执行完毕后,将显存中的结果从device拷贝回主机内存中,再进行其他的操作(保存,打印,展示等)。
③GPU程序执行完毕后,将显存中的结果从device拷贝回主机内存中,再进行其他的操作(保存,打印,展示等)。 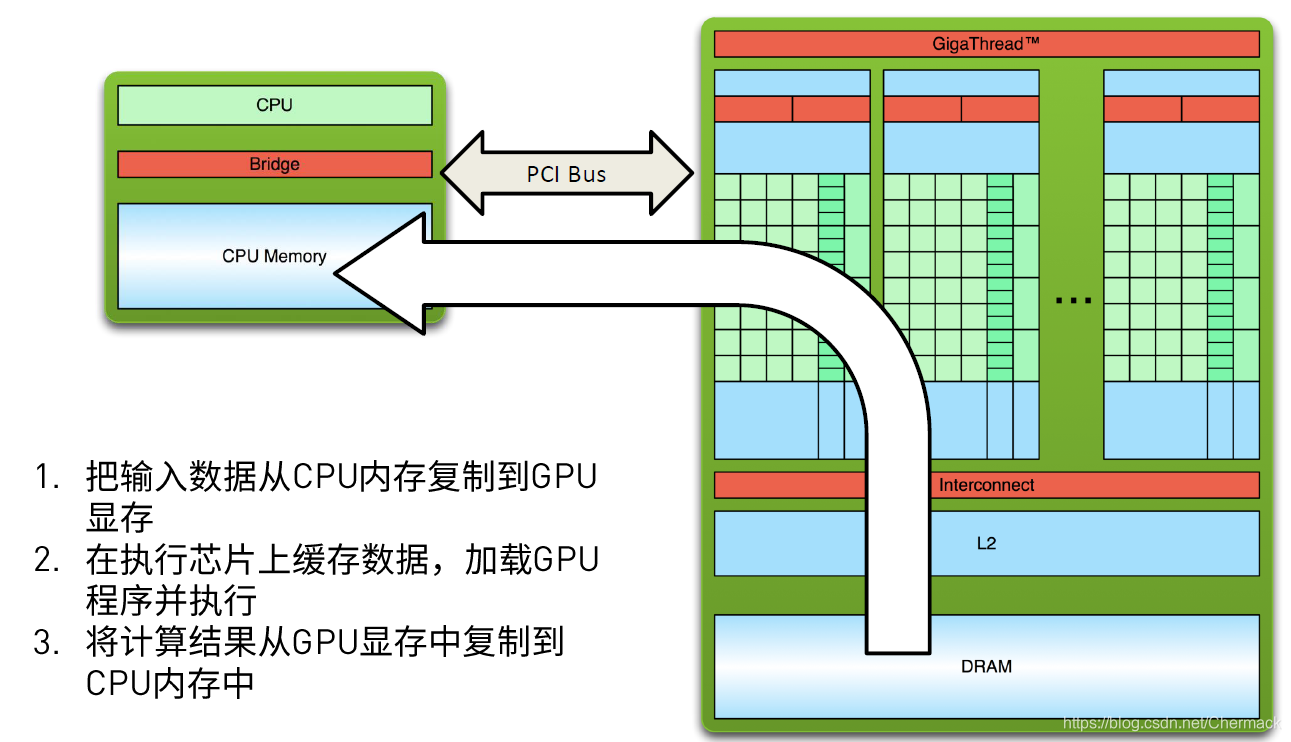 上面三步便是GPU编程的基本步骤,可以总结出一个简单的异构计算流程如下:先顺序执行CPU代码,遇到耗时的可以并行执行的程序时,采用GPU并行编程,然后回到CPU顺序执行处理逻辑,如此反复进行。
上面三步便是GPU编程的基本步骤,可以总结出一个简单的异构计算流程如下:先顺序执行CPU代码,遇到耗时的可以并行执行的程序时,采用GPU并行编程,然后回到CPU顺序执行处理逻辑,如此反复进行。 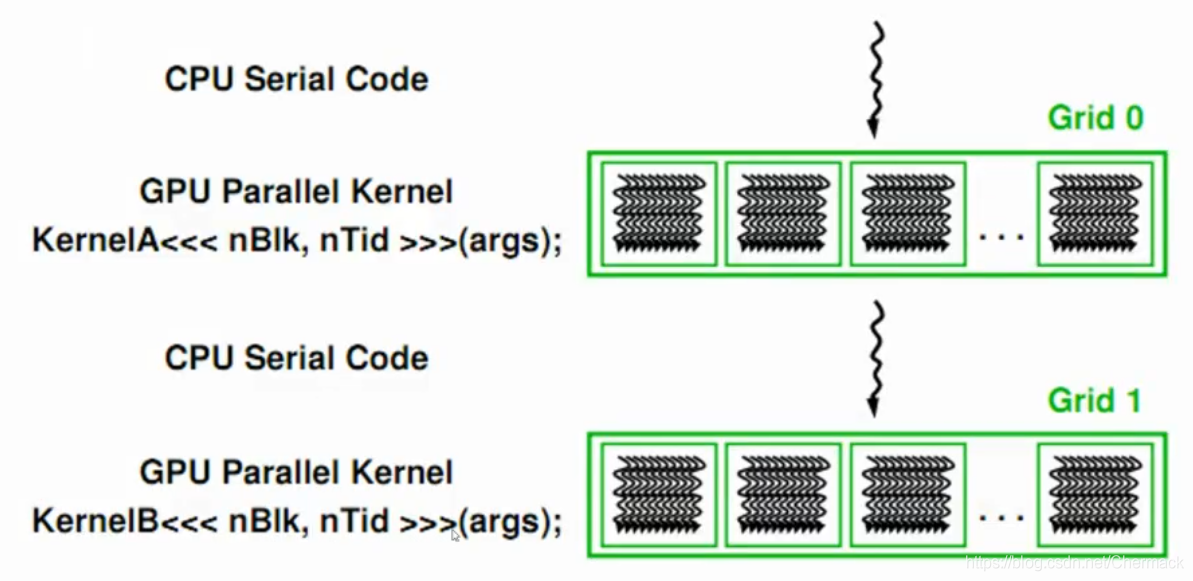
 在默认情况下,执行一个GPU并行计算任务时,一个Thread对应于一个Thread Processor,即硬件里面的一个处理器核心。一个Block会对应一个SM单元。一个Grid则对应了一个GPU设备,如下所示:
在默认情况下,执行一个GPU并行计算任务时,一个Thread对应于一个Thread Processor,即硬件里面的一个处理器核心。一个Block会对应一个SM单元。一个Grid则对应了一个GPU设备,如下所示: 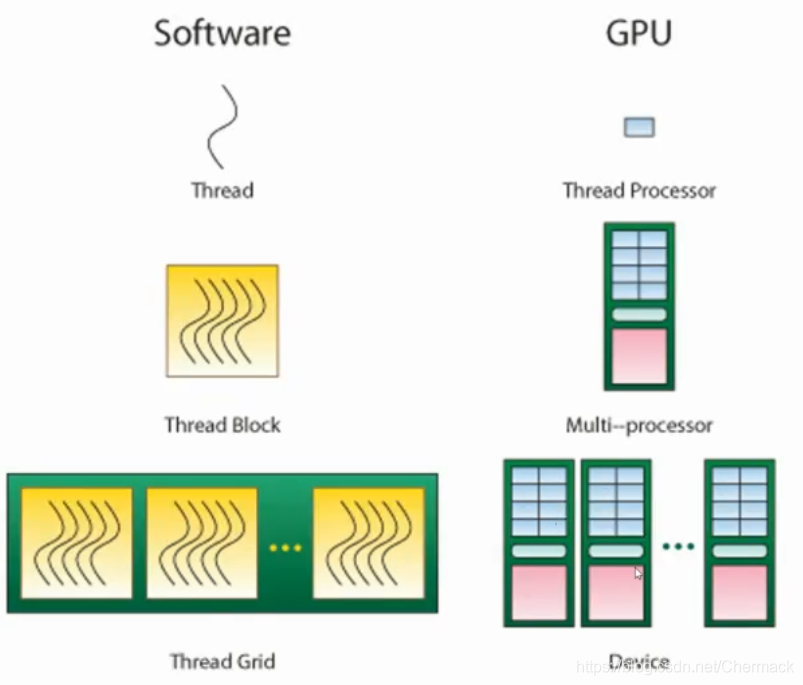
【本文地址】